Robotic manipulation in open-world settings demands not only the execution of tasks but also the ability to detect and learn from failures during execution. While recent advances in vision-language models (VLMs) and large language models (LLMs) have enhanced robots' spatial reasoning and problem-solving capabilities, these models often struggle to recognize and reason about failures, limiting their effectiveness in real-world applications. In this paper, we introduce AHA, an open-source VLM specifically designed to detect and reason about failures in robotic manipulation through natural language. By framing failure detection as a free-form reasoning task, AHA identifies failures and generates detailed explanations adaptable across various robots, tasks, and environments in both simulation and real-world scenarios. To fine-tune Aha, we developed FailGen, a scalable simulation framework that procedurally generates the AHA dataset — the first large-scale dataset of robotic failure trajectories—by perturbing successful demonstrations from the RLBench simulator. Despite being trained solely on the AHA dataset, AHA generalizes effectively to real-world failure datasets, different robotic systems, and unseen tasks. It surpasses the second-best model by 10.3% and exceeds the average performance of all six compared models—including five state-of-the-art VLMs and one model employing in-context learning—by 35.3% across multiple metrics and datasets. Moreover, we integrate AHA into three VLM/LLM-assisted manipulation frameworks. Its natural language failure feedback enhances error recovery and policy performance through methods such as improving reward functions with Eureka reflection, optimizing task and motion planning, and verifying sub-task success in zero-shot robotic manipulation. Our approach achieves an average task success rate 21.4% higher than GPT-4 models. Our contributions are threefold: (1) developing FailGen and curating the AHA dataset, enabling scalable procedural generation of failure demonstrations; (2) instruction-tuning AHA for advanced failure reasoning in manipulation tasks, outperforming existing models; and (3) integrating AHA into downstream robotic systems, demonstrating improved error correction and policy performance.
The data generation for AHA is accomplished by taking a normal task trajectory in simulation and procedurally perturbing all keyframes using our taxonomy of failure modes. Through FailGen, we systematically alter keyframes to synthesize failure demonstrations conditioned on the original tasks. Simultaneously, we generate corresponding query and answer prompts for each task and failure mode, which are used for instruction-tuning. (Bottom) The instruction-tuning pipeline follows the same fine-tuning procedure as LLaVA-v1.5, where we fine-tune only the LLM base model—in this case, LLaMA-2-13B and the projection linear layers, while freezing the rest of the model.
AHA-13B Outperforms 6 SoTA VLMs in Failure reasoning for robotic manipulation Across 3 diverse datasets and 4 evaluation metrics.
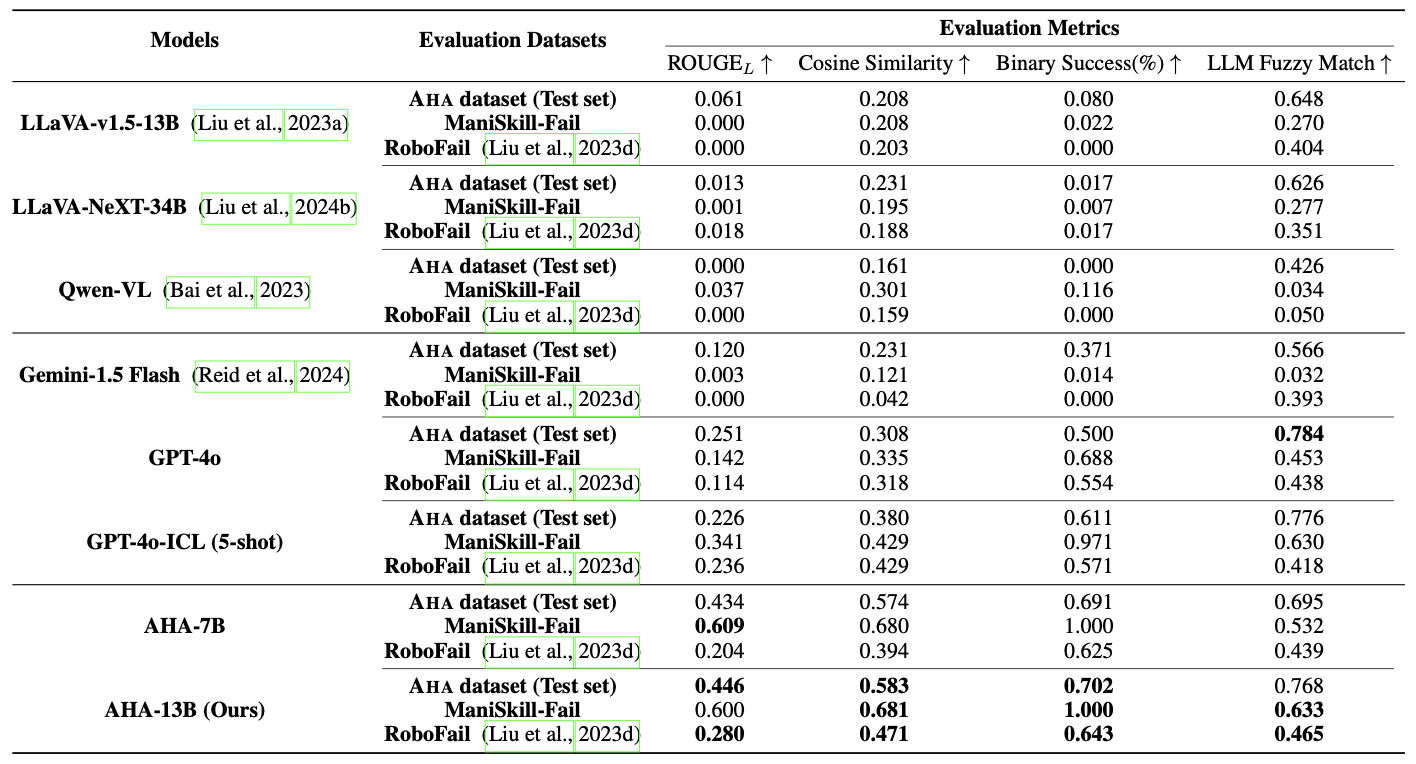
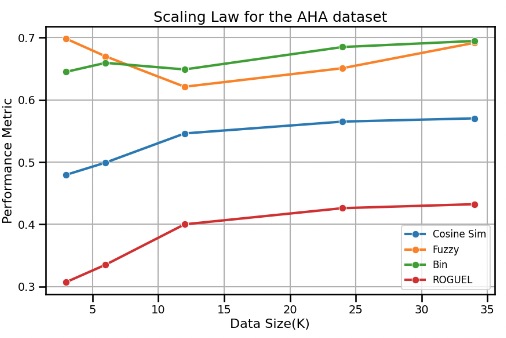
AHA scales in performance with data
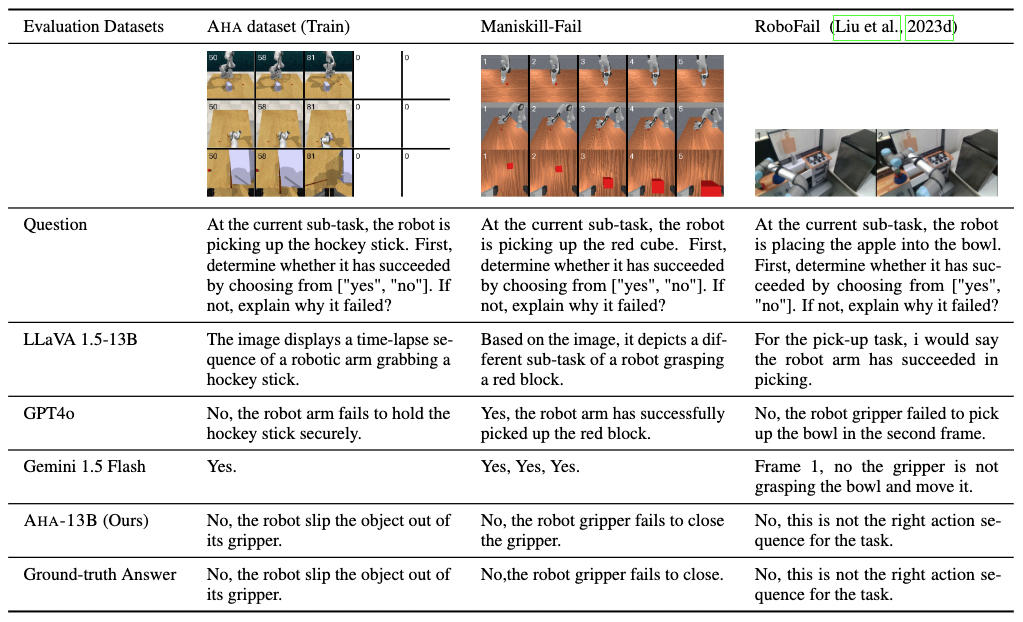
AHA generalizes failure reasoning across embodiments, unseen domains, and novel tasks.
VLM Reward Function Generation (Eureka)
![<b>Task: Pick up the mustard bottle</b>, AHA Improved Reward Function:
[sep]
static/txt/reward_functions/maniskill/task1.txt](static/videos/maniskill/task1.png)
![<b>Task: Push T to shaped T area</b>, AHA Improved Reward Function:
[sep]
static/txt/reward_functions/maniskill/task2.txt](static/videos/maniskill/task2.png)
![<b>Task: Put sphere into sphere holder</b>, AHA Improved Reward Function:
[sep]
static/txt/reward_functions/maniskill/task3.txt](static/videos/maniskill/task3.png)
![<b>Task: Stack the red cube onto the green cube</b>, AHA Improved Reward Function:
[sep]
static/txt/reward_functions/maniskill/task4.txt](static/videos/maniskill/task4.png)
![<b>Task: Open the drawer</b>, AHA Improved Reward Function:
[sep]
static/txt/reward_functions/maniskill/task5.txt](static/videos/maniskill/task5.png)
VLM Task-plan Generation (PRoC3S)
![<b>Task: Stack banana onto spam can</b>, AHA Improved Task-plan:
[sep]
static/txt/reward_functions/tamp/t1.txt](static/videos/tamp/t1.png)
![<b>Task: Stack two cubes inside a bowl</b>, AHA Improved Task-plan:
[sep]
static/txt/reward_functions/tamp/t2.txt](static/videos/tamp/t2.png)
![<b>Task: Move the banana to the centre</b>, AHA Improved Task-plan:
[sep]
static/txt/reward_functions/tamp/t3.txt](static/videos/tamp/t3.png)
VLM Sub-task Verification (Manipulate Anything)



 AHA:
AHA: